
Reproducibility in NLP Research - Why and how? - Part 1
In our group’s reading group, we recently discussed the following paper:
A Systematic Review of Reproducibility Research in Natural Language Processing
Authors: Anya Belz, Shubham Agarwal, Anastasia Shimorina, Ehud Reiter
Publication Venue/Date: EACL 2021
ArXiv Pre-print url
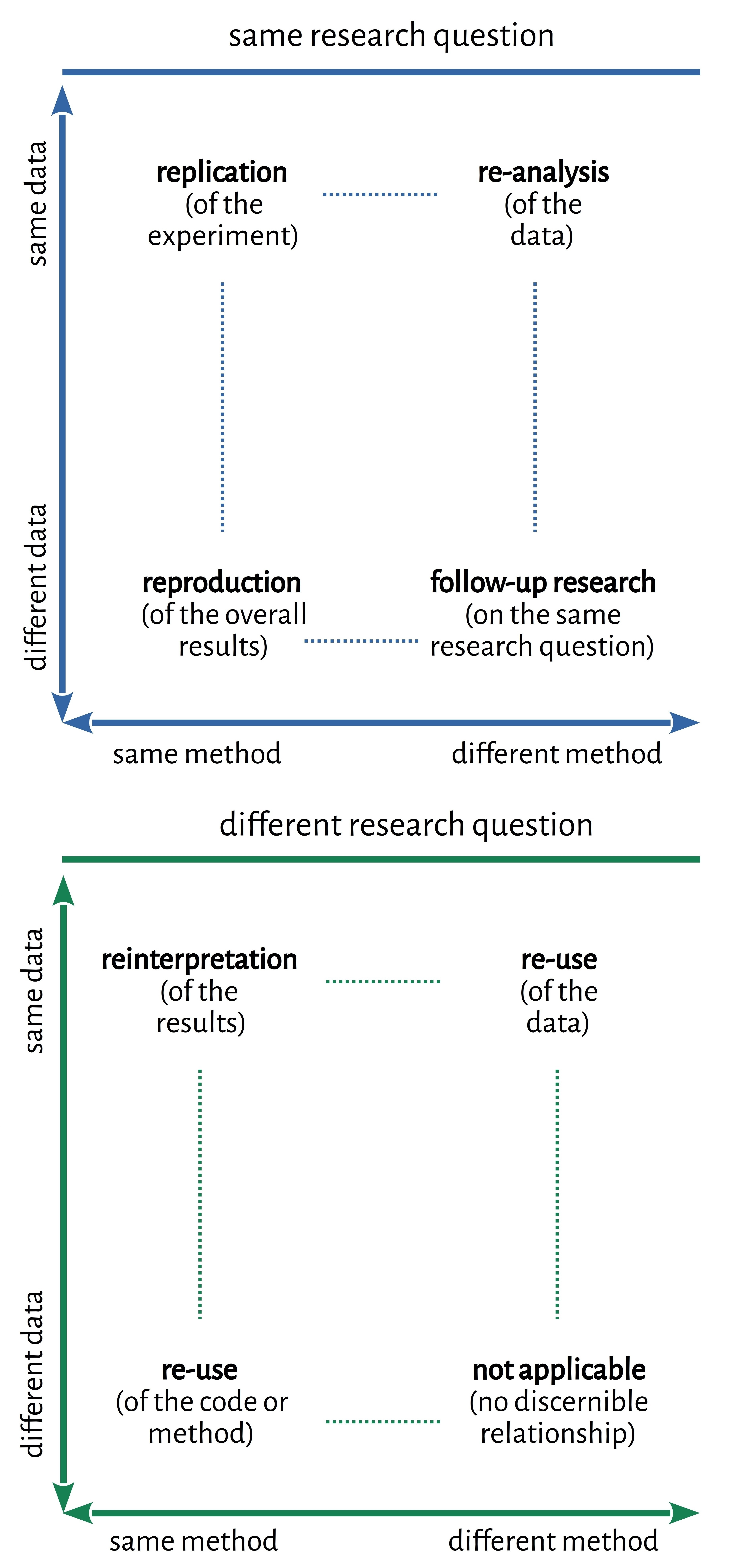
But this post is not really about this paper! :-) and one can look up the paper for the definition of what reproducibility means in NLP and its many facets … or quickly look at this typology of replication studies.
{kind=link}
While discussing the paper, an interesting argument came up, which can be summarized as: “Reproducibility need not necessarily be as serious of a concern for us (i.e., NLP) as it is in other fields such as psychology or medicine. We are more about “ideas”, and a bad idea will not survive even if it reproducible, a good idea will, even if the initial implementation had some reproducibility issues”.
I agree with the “ideas” part. However, I still think reproducibility related work is very important for NLP research. In this blog post, I am trying to clear my thoughts and write about why I think it is still important, but for reasons different (or unrelated) to the reproducibility crisis discussions in other disciplines.
Before going further, I would like to point to a few precedents from recent years for this reproducibility discussion in fields such as NLP and Machine Learning:
- ICML 2018 workshop on reproducible machine learning
- NeurIPS 2019 reproducibility program
- ML Reproducibility Challenge 2020
- REPROLANG 2020, which specifically focuses on NLP, and its previous versions
There is a lot of research published in recent years on the topic beyond these shared tasks. So, clearly there are people within these fields that think this is an important issue.
Reproducibility and NLP: Why?
Clearly, the very word gives a vibe that you are just trying to repeat something that is already done, so there is nothing new or interesting there. Then, why bother? I would like to put forth three scenarios I can think of, where it is important:
Scenario 1:
This is a “within NLP” scenario: Team A took a popular NLP dataset, with an established train-dev-test split, and developed a new neural network architecture, and showed an accuracy of 90% on this dataset. The previous best reported result was 89%, with another neural architecture, on this same split. Now, we don’t normally report significances and other statistical tests, so, Team A’s becomes the new SOTA (state of the art) for that task. Now, a new team C wants to build another new algorithm for this same task, and during their experiments, they got an accuracy of 89.5% on the same test set. When they tried to replicate Team A’s results to establish their own benchmarks, they got a result of 89.3%.
At this point, there are a few thoughts that one may get, and I am being a particularly mean reviewer:
- This Team C perhaps did not do the replication of Team A properly. Does that mean there are flaws in their own implementation too? Is this the new SOTA or is Team A’s still that thing?
- Looks like this Team C has done a great job. But replication of Team A’s results has a discrepancy. Does that mean this Team A did not do their due diligence, and hence, they never were the SOTA?
A cynical reviewer (me?): 89.3, 89.5, 90 - big deal. They all may be statistically no different from each other. Perhaps if the test sample is slightly different, the numbers may also be very different. If we run the same experiment changing some hyper parameters (or worse: random seeds), we may end of with drastically different. So many ways to doubt if these differences are really real!
In this scenario, I don’t think anyone is doing anything wrong in terms of their implementation of their ideas. However, we perhaps can openly embrace the idea that there is no SOTA, but there can be SOTAs. Reproducibility in various forms (same data, different methods; same data, same method, varying small parameters; different test sets, same training set etc) can help us understand this SOTA, its merits and limitations. So, reproducibility research will inform and make NLP research better.
Scenario 2:
This is a “NLP as a research method for some other research area” scenario: Team A developed an approach describing a way to extract information about study designs from medical journals. This turned out to set a new benchmark on that task, and became the SOTA. Impressed by Team A’s work, a medical researcher wants to use it, with the goal of doing a systematic review of some medical issue, to inform policy decisions. They found out, however, that this SOTA isn’t doing as well on this new custom dataset relevant to the problem at hand. However, this is the SOTA in NLP on this problem. There are several other non-SOTA methods, some too simple to believe they work, some too complex that there is no way of deploying these into some tool even if they work. How can we choose among them if SOTA itself is bad?
This scenario is also where published work on reproducibility from scenario 1 is extremely valuable and informative, in my opinion. We will then know there are alternatives that may also potentially work, while also being the state of the art (and not some fishy method no one uses anyway). So, reproducibility is actually a useful issue to study, even if we think of NLP’s applicability beyond its own domain.
Scenario 3:
This is a “NLP in Industry” scenario. There is a company, which is your regular technology company without large scale R&D teams. So, here is our Engineer A, who works on developing some NLP component for some new product/client project etc. She faces a new problem, for which she can’t figure out a solution yet and they decide that it looks like some research problem, without an established solution yet. While hunting for potential solutions, she stumbles upon ACL Anthology, which is a non-paywalled wonder world of SOTA NLP research. She quickly finds a paper with MIT-licensed code that she can quickly use to prototype a solution without compromising on the company’s stuff. This is great, the code runs, and although the results are different because she is using it for her company’s dataset, she realizes that this wonderful solution can never be put to work in their production environment due to various implementation issues. So, is all NLP research that is not deployable, but is still SOTA, pure junk?
This scenario is also where published work on reproducibility helps these engineers, who need not necessarily be researchers themselves, make informed decisions on what to choose among the NLP SOTAs for their particular scenario.
To summarize, I think reproducibility issues in NLP (as well as ML, considering the overlap of methods) are their own special cases, and I don’t think these are the same concerns other disciplines who also worry about reproducibility issues have. Further, working on these issues have far reaching implications beyond NLP research itself, benefiting various groups of applied NLP researchers and engineers. We may not have to worry about effect sizes and p-values and stuff in NLP, but we have other things to worry even if we treat this whole thing as purely an engineering endeavour with or without concern for the science part of it. I will end here, with a disclaimer that these are not my final thoughts on this topic, and they are evolving. I am writing for my own clarity and not for educating others. At this point, I am considering on writing another post on the question: “How can one support reproducibility in NLP?”